- The Analytics Lens
- Posts
- Build Your First Decision Tree
Build Your First Decision Tree
Focus on how decision trees work | E2
The Analytics Lens
October 29, 2024
Read Time - 3.5 mins
Hii,
Welcome to the new edition of The Analytics Lens !!
In this edition, we’re diving into one of the most intuitive machine learning models: Decision Trees! These trees are popular for their simplicity, interpretability, and versatility, making them ideal for beginners and seasoned data scientists alike. Whether you’re optimizing customer segmentation or predicting loan defaults, decision trees are an accessible and powerful tool to have in your analytics toolkit.
Grab a coffee, and let’s start from scratch!
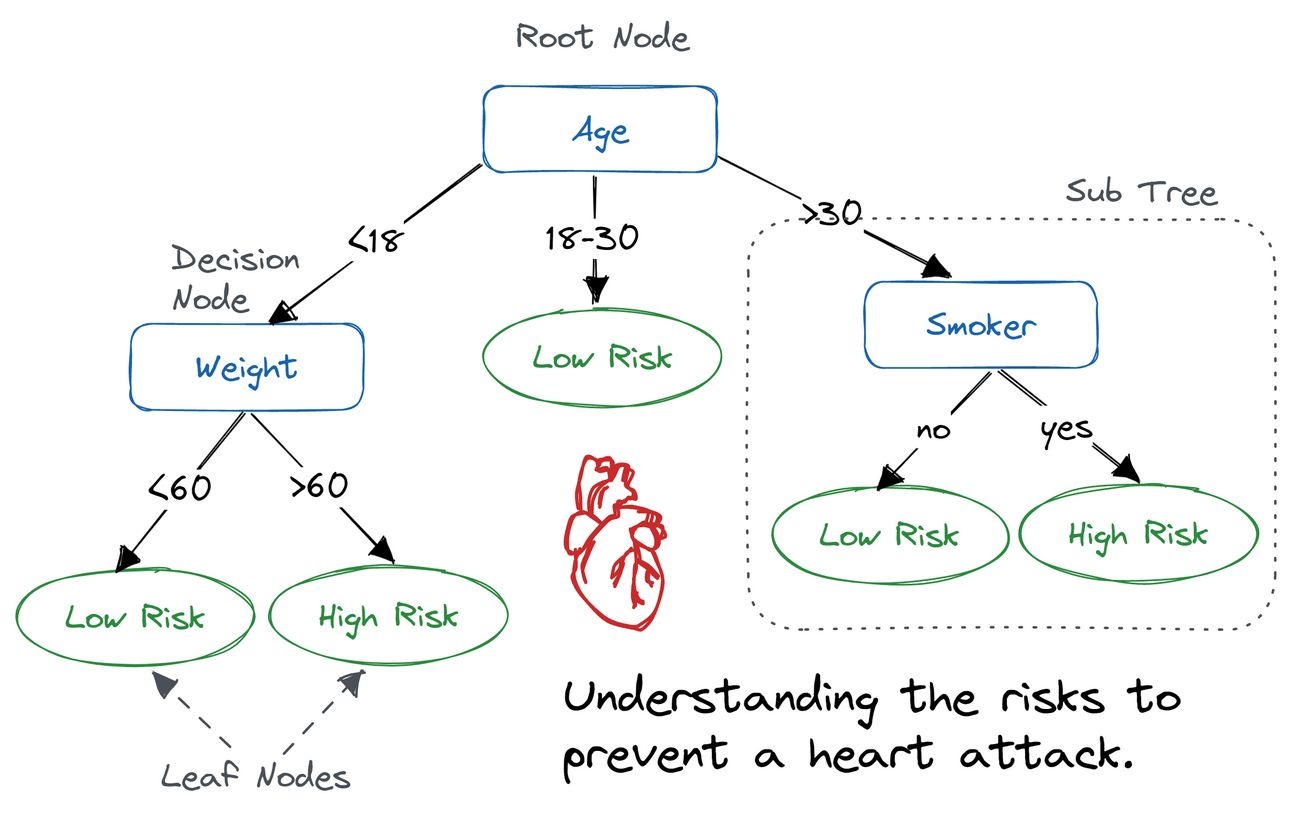
What’s a Decision Tree Anyway?
Imagine you’re a loan officer deciding whether to approve a loan. You start by checking if the applicant has a stable job, then look at their credit score, and perhaps their loan history. This sequence of decisions can be visualized as a "tree" where each “branch” represents a question and each “leaf” represents an outcome.
A decision tree essentially does this, but with data guiding each decision point. The result? A model that’s easy to interpret, explain, and apply across various fields.
How Decision Trees Work: Breaking Down the Process
At its core, a decision tree operates on a series of binary questions, creating splits in data until it reaches a conclusion. Here’s the process broken down into key stages:
1. Splitting Criteria
When building a decision tree, we need a way to decide the best "question" or split at each stage. This is where metrics like Gini Impurity and Entropy come into play. These metrics evaluate how well each potential split separates the data into distinct classes, aiming to reduce the "impurity" in each group.
Example:
For binary classification, a Gini Impurity score close to 0 indicates a pure group, while a higher score (closer to 0.5) suggests a mix of classes.
In simple terms, Gini Impurity helps the tree decide which features (variables) are the most useful in distinguishing between groups, allowing it to create clearer, more informative branches.
2. Depth Control
The depth of a tree impacts its performance significantly. If you allow a tree to grow deep without limits, it will likely overfit—meaning it will capture noise along with patterns, performing well on training data but poorly on new data. Conversely, a very shallow tree may underfit, failing to capture complex relationships.
Maximum Depth: Setting a maximum depth allows the tree to focus on important splits without becoming overly complex.
Minimum Samples per Leaf: Setting a minimum number of samples per leaf ensures that each decision has enough data to be statistically sound.
Think of this step as pruning branches of a real tree—leaving only the strongest branches helps the tree thrive.
Building Your First Decision Tree: A Step-by-Step Guide
Let’s walk through a simple example using Python's Scikit-learn library to build a decision tree.
Step 1: Import Libraries

Step 2: Prepare Your Data

Step 3: Encode Categorical Data

Step 4: Split the Data

Step 5: Build and Train the Model

Step 6: Make Predictions

Explanation:
We create a small dataset that reflects factors influencing a fruit’s label (name).
The DecisionTreeClassifier with
max_depth=3helps prevent overfitting.The accuracy score lets us evaluate how well the model has performed on unseen test data.
Try experimenting with different max_depth values or other features to see how the model changes!
Common Pitfalls
While decision trees are powerful tools, they come with challenges:
Overfitting: As mentioned earlier, deep trees can memorize training data rather than generalize from it. Pruning techniques can help reduce complexity.
Bias towards features with more levels: Decision trees can be biased towards features that have more categories (e.g., categorical variables), so careful feature selection is crucial.
Practical Applications of Decision Trees
Decision trees are versatile and applicable across various fields:
Healthcare: Predicting disease outcomes based on patient data.
Finance: Assessing credit risk by analyzing customer profiles.
Marketing: Segmenting customers based on purchasing behavior.
Recommended Reads for further exploration
For those eager to dive deeper into decision trees and their applications, here are three recommended articles:
Decision Tree in Machine Learning - A comprehensive guide on building decision trees.
What is a Decision Tree in Machine Learning? - A step-by-step explanation of how decision trees work.
Decision Trees in Machine Learning - An overview of decision trees with examples and applications.
Recommended Video (Learn intuitively about Decision Trees)
Prompt of the Day
Input this prompt on hatGpt. You will receive an interesting output.
Imagine you are a data analyst working for a major e-commerce company. Your task is to build a decision tree to help categorize customers based on their purchase behavior, browsing patterns, and demographic information. Explain the step-by-step approach you’d take to set up this model, the factors you’d consider in tuning the tree, and the metrics you'd use to assess its performance. Describe the impact of different customer groups on the business, and offer recommendations based on the insights from your decision tree analysis.
Thank you for joining us in exploring decision trees! We hope this guide has sparked your interest in machine learning and provided you with valuable insights. Happy learning!
My knowledge base after reading the newsletter of The Analytics Lens

Reply